Mike Bursell
This article is a slightly edited version of an article originally published at https://blog.enarx.dev/confidential-computing-logging-and-debugging/
Debugging applications is an important part of the development process, and one of the mechanisms we use for it is logging: providing extra details about what’s going on in (and around) the application to help us understand problems, manage errors and (when we’re lucky!) monitor normal operation. Logging then, is useful not just for abnormal, but also for normal (“nominal”) operations. Log entries and other error messages can be very useful, but they can also provide information to other parties – sometimes information which you’d prefer they didn’t have. This is particularly true when you are thinking about Confidential Computing: running applications or workloads in environments where you really want to protect the confidentiality and integrity of your application and its data. This article examines some of the issues that we need to consider when designing Confidential Computing frameworks, the applications we run in them, and their operations. It is written partly from the point of view of the Enarx project, but that is mainly to provide some concrete examples: these have been generalised where possible. Note that this is quite a long article, as it goes into detailed discussion of some complex issues, and tries to examine as many of the alternatives as possible.
First, let us remind ourselves of one of the underlying assumptions about Confidential Computing in general which is that you don’t trust the host. The host, in this context, is the computer running your workload within a TEE instance – your Confidential Computing workload (or simply workload). And when we say that we don’t trust it, we really mean that: we don’t want to leak any information to the host which might allow it (the host) to infer information about the workload that is running, either in terms of the program itself (and any associated algorithms) or the data.
Now, this is a pretty tall order, particularly given that the state of the art at the moment doesn’t allow for strong protections around resource utilisation by the workload. There’s nothing that the workload can do to stop the host system from starving it of CPU resources, and slowing it down, or even stopping it running altogether. This presents the host with many opportunities for artificially imposed timing attacks against which it is very difficult to protect. In fact, there are other types of resource starvation and monitoring around I/O as well, which are also germane to our conversation.
Beyond this, the host system can also attempt to infer information about the workload by monitoring its resource utilisation without any active intervention. To give an example, let us say that the host notices that the workload creates a network socket to an external address. It (the host) starts monitoring the data sent via this socket, and notices that it is all encrypted using TLS. The host may not be able to read the data, but it may be able to infer that a specific short burst of activity just after the opening of the socket corresponds to the generation of a cryptographic key. This information on its own may be sufficient for the host to fashion passive or active attacks to weaken the strength of this key.
None of this is good news, but let’s extend our thinking beyond just normal operation of the workload and consider debugging generally and the error handling more particularly. For the sake of clarity, we will posit a tenant with a client process on a separate machine (considered trusted, unlike the host), and that TEE instance on the host has four layers, including the associated workload. This may not be true for all applications or designs, but is a useful generalisation, and covers most of the issues that are likely to arise. This architecture models a cloud workload deployment. Here’s a picture.
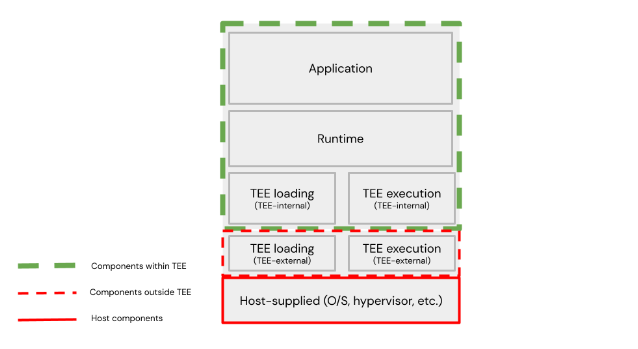
TEE layers and components
These layers may be defined thus:
- application layer – the application itself, which may or may not be aware that it is running within a TEE instance. For many use cases, this, from the point of view of a tenant/client of the host, is the workload as defined above.
- runtime layer – the context in which the application runs. How this is considered is likely to vary significantly between TEE type and implementations, and in some cases (where the workload is a full VM image, including application and operating system, for instance), there may be little differentiation between this layer and the application layer (the workload includes both). In many cases, however, the runtime layer will be responsible for loading the application layer – the workload.
- TEE loading layer – the layer responsible for loading at least the runtime layer, and possibly some other components into the TEE instance. Some parts of this are likely to exist outside of the TEE instance, but others (such as a UEFI loader for a VM) may exist within it. For this reason, we may choose to separate “TEE-internal” from “TEE-external” components within this layer. For many implementations, this layer may disappear (cease to run and be removed from memory) once the runtime has started.
- TEE execution layer – the layer responsible for actually executing the runtime above it, and communicating with the host. Like the TEE loading layer, this is likely to exist in two parts – one within the TEE instance, and one outside it (again, “TEE-internal” and “TEE-external”.
An example of relative lifecycles is shown here.
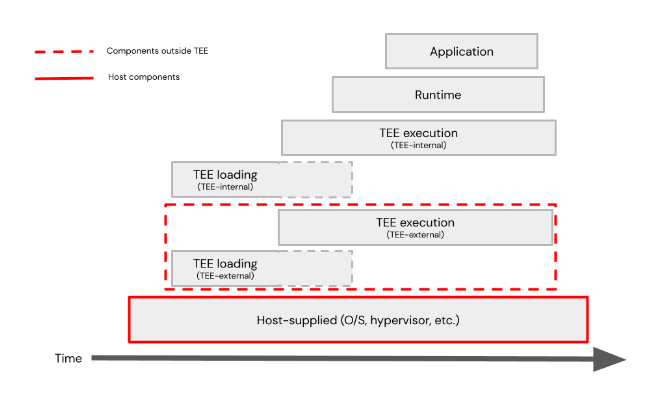
Component lifecycles
Now we consider logging for each of these.
Application layer
The application layer generally communicates via a data plane to other application components external to the TEE, including those under the control of the tenant, some of which may sit on the client machine. Some of these will be considered trusted from the point of view of the application, and these at least will typically require an encrypted communication channel so that the host is unable to snoop on the data (others may also require encryption). Exactly how these channels are set up will vary between implementations, but application-level errors and logging should be expected to use these communication channels, as they are relevant to the application’s operation. This is the simplest case, as long as channels to external components are available. Where they cease to be available, for whatever reason, the application may choose to store logging information for later transfer (if possible) or communicate a possible error state to the runtime layer.
The application may also choose to communicate other runtime errors, or application errors that it considers relevant or possibly relevant to runtime, to the runtime layer.
Runtime layer
It is possible that the runtime layer may have access to communication channels to external parties that the application layer does not – in fact, if it is managing the loading and execution of the runtime layer, this can be considered a control plane. As the runtime layer is responsible for the execution of the application, it needs to be protected from the host, and it resides entirely within the TEE instance. It also has access to information associated with the application layer (which may include logging and error information passed directly to it by the application), which should also be protected from the host (both in terms of confidentiality and integrity), and so any communications it has with external parties must be encrypted.
There may be a temptation to consider that the runtime layer should be reporting errors to the host, but this is dangerous. It is very difficult to control what information will be passed: not only primary information, but also inferred information. There does, of course, need to be communication between the runtime layer and the host in order to allow execution – whether this is system calls or another mechanism – but in the model described here, that is handled by the TEE execution layer.
TEE loading layer
This layer is one where we start having to make some interesting decisions. There are, as we noted, two different components which may make up this layer: TEE-internal and TEE-external.
TEE loading – TEE-internal
The TEE-internal component may generate logging information associated either with successful or unsuccessful loading of a workload. Some errors encountered may be recoverable, while others are unrecoverable. In most cases, it may generally be expected that a successful loading event is considered non-sensitive and can be exposed to the TEE-external component, as the host will generally be able to infer successful loading as execution will continue onto the next phase (even when the TEE loading layer and TEE execution layer do have not explicitly separate external components), but the TEE-internal component still needs to be careful about the amount of information exposed to the host, as even information around workload size or naming may provide a malicious entity with useful information. In such cases, integrity protection of messages may be sufficient: failure to provide integrity protection could lead the host to misreport successful loading to a remote tenant, for example – not necessarily a major issue, but a possible attack vector nevertheless.
Error events associated with failure to load the workload (or parts of it) are yet more tricky. Opportunities may exist for the host to tamper with the loading process with the intention of triggering errors from which information may be gleaned – for instance, pausing execution at particular points and seeing what error messages are generated. The more data exported by the TEE loading internal component, the more data the external component may be able to make available to malicious parties. One of the interesting questions to consider is what to do with error messages generated before a communications channel (the control plane) back to the provisioning entity has been established. Once this has been established (and is considered “secure” to the appropriate level required), then transferring error messages via it is a pretty straightforward proposition, though this channel may still be subject to traffic analysis and resource starvation (meaning that any error states associated with timing need to be carefully examined). Before this communication channel has been established, the internal component has three viable options (which are not mutually exclusive):
- Pass to the external component for transmission to the tenant “out of band”, by the external component.
- Pass to the external component for storage and later consumption and transmission over the control plane by the internal component if the control plane can be established in the future.
- Consign to internal storage, assuming availability of RAM or equivalent assigned for this purpose.
In terms of attacks, options 1 and 2 are broadly similar as long as the control plane fails to exist. Additionally, in case 1, the external component can choose not to transmit all (or any) of the data to the tenant, and in case 2, it may withhold data from the internal component when requested.
If we take the view (as proposed above) that at least the integrity, and possibly the confidentiality of error messages is of concern, then option 1 would only be viable if a shared secret has already been established between the TEE loading internal component and the tenant or the identity of the TEE loading internal component already established with the tenant, which is impossible unless the control plane has already been created. For option 2, the internal component can generate a key which it can use to encrypt the data sent to the external component, and store this key for decryption when (and if) the external component returns the data.
TEE loading – TEE-external
Any information which is available to any TEE-external component must be assumed to be unprotected and untrusted. The only exceptions are if data is signed (for integrity) or encrypted (for confidentiality, though integrity is typically also transparently assured when data is encrypted), as noted above. The TEE-external may choose to store or transmit error messages from the TEE-internal component, as noted above, but it may also generate log entries of its own. There are five possible (legitimate) consumers of these entries:
- The host system – the host (general logging, operating system or other components) may consume information around successful loading to know when to start billing, for instance, or consume information around errors for its own purposes or to transmit to the tenant (where the TEE loading component is not in direct contact with the client, or other communication channels are preferred).
- The TEE loading internal component – there may be both success and failure events which are useful to communicate to the TEE loading internal component to allow it to make decisions. Communications to this component assume, of course, that loading was sufficiently successful to allow the TEE loading internal component to start execution.
- The TEE runtime external component – if the lifecycle has proceeded to the stage where the TEE runtime component is executing, the TEE loading external component can communicate logging information to it, either directly (if they are executing concurrently) or via another entity such as storage.
- The TEE runtime internal component – similarly to case #3 above, the TEE loading external component may be able to communicate to the TEE runtime internal component, either directly or indirectly.
- The client – as noted in #1 above, the host may communicate logging information to the client. An alternative, if an appropriate communications channel exists, is for the TEE loading external component to communicate directly with it. The client should always treat all communications with this component as untrusted (unless they are being transmitted for the internal component, and are appropriately integrity/confidentiality protected).
The TEE runtime layer
TEE runtime – TEE-internal
While the situation for this component is similar to that for the TEE loading internal component, it is somewhat simpler because the fact that this stage of the lifecycle has been reached means that the application has, by definition, been loaded and is running. This means that there are a number of different channels for communication of error messages: the application data plane, the runtime control plane and the TEE runtime external component. Most logging information will generally be directed either to the application (for decision making or transmission over its data plane at the application’s discretion) or to the client via the control plane. Standard practice can generally be applied as to which of these is most appropriate for which use cases.
Transmission of data to the TEE runtime external component needs to be carefully controlled, as the runtime component (unless it is closely coupled with the application) is unlikely to be in a good position to judge what information might be considered sensitive if available to components or entities external to the TEE. For this reason, either error communication to the TEE runtime external component should be completely avoided, or standardised (and carefully designed) error messages should be employed – which makes standard debugging techniques extremely difficult.
Debugging
Any form of debugging for TEE instances is extremely difficult, and there are two fairly stark choices:
- Have a strong security profile and restrict debugging to almost nothing.
- Have a weaker security profile and acknowledge that it is almost impossible to ensure the protection of the confidentiality and integrity of the workload (the application and its data).
There are times, particularly during the development and testing of a new application when the latter is the only feasible approach. In this case, we can recommend two principles:
- Create a well-defined set of error states which can be communicated via untrusted channels (that is, which are generally unprotected from confidentiality and integrity attacks), and which do not allow for “free form” error messages (which are more likely to leak information to a host).
- Ensure that any deployment with a weaker profile is closely controlled (and never into production).
These two principles can be combined, and a deployment lifecycle might allow for different profiles: e.g. a testing profile on local hardware allowing free form error messages and a staging profile on external hardware which only allows for “static” error messages.
Standard operation
Standard operation must assume the worst case scenario, which is that the host may block, change and interfere with all logging and error messages to which it has access, and may use them to infer information about the workload (application and associated data), affecting its confidentiality, integrity and normal execution. Given this, the default must be that all TEE-internal components should minimise all communications to which the host may have access.
Application
To restrict application data plane communication is clearly infeasible in most cases, though all communications should generally be encrypted for confidentiality and integrity protection and designers and architects with particularly strong security policies may wish to consider how to restrict data plane communications.
Runtime component
Data plane communications from the runtime component are likely to be fewer than application data plan communications in most cases, and there may also be some opportunities to design these with security in mind.
TEE loading and TEE runtime components
These are the components where the most care must be taken, as we have noted above, but also where there may be the most temptation to lower levels of security if only to allow for easier debugging and error management.
Summary
In a standard cloud deployment, there is little incentive to consider strong security controls around logging and debugging, simply because the host has access not only to all communications to and from a hosted workload, but also to all the code and data associated with the workload at runtime. For Confidential Computing workloads, the situation is very different, and designers and architects of the TEE infrastructure and even, to a lesser extent, of potential workloads themselves, need to consider very carefully the impact of the host gaining access to messages associated with the workload and the infrastructure components. It is, realistically, infeasible to restrict all communication to levels appropriate for deployment, so it is recommended that various profiles are created which can be applied to different stages of a deployment, and whose use is carefully monitored, logged (!) and controlled by process.





